小团队如何用 Grafana 搭建简单好用的监控告警
背景
很多小团队一提到监控就头大——要部署 Prometheus、要配 Alertmanager、要写 PromQL……搞一套下来比写业务代码还复杂。
其实如果你只是想知道”订单量有没有骤跌””数据库连接数高不高””磁盘快爆了没”,一个 Grafana 就够了。
为什么是 Grafana?
Grafana 8 之后内置了完整的告警引擎,不再依赖外部 Alertmanager。对于小团队来说,它能带来三个好处:
一站式:数据展示和告警在同一个地方搞定,不用来回切系统。
多数据源:MySQL、PostgreSQL、Redis 都能直接连,不局限于 Prometheus。
开箱即用的通知:企业微信、钉钉、飞书、邮件都支持,不用额外装插件。
三步搞定监控告警
第一步:安装 Grafana
最简单的方式用 Docker:
1 | docker run -d \ |
打开 http://localhost:3000,默认账号密码都是 admin。
如果是 macOS,也可以用 Homebrew:
1 | brew install grafana |
第二步:接入 MySQL 数据源
Grafana 支持几十种数据源,对于小团队来说,最实用的场景是直接连业务数据库做监控。以 MySQL 为例:
添加数据源
路径:左侧菜单 → Connections → Data sources → Add data source → 选择 MySQL。
填写连接信息:
- Host:
your-mysql-host:3306 - Database:
your_db - User:给 Grafana 创建一个只读账号,只授 SELECT 权限,避免误操作
1 | CREATE USER 'grafana'@'%' IDENTIFIED BY 'your_password'; |
点 Save & test,显示 “Database Connection OK” 就搞定了。
小贴士:除了 MySQL,PostgreSQL、Redis 的接入方式也类似,在数据源列表里选对应的类型填连接信息就行。如果需要监控服务器 CPU、磁盘等系统指标,可以装一个 Grafana Agent 来采集。
第三步:配置告警
这是最关键的一步。Grafana 8+ 的告警分两部分:告警规则和通知策略。
1. 写告警规则
进入 Alerting → Alert rules → New alert rule。
一个告警规则核心就三要素:
- 查询条件:从数据源取一个值,比如最近 5 分钟的订单量
- 阈值:低于多少算异常,比如小于 10 单
- 持续时间:连续异常多久才告警,比如持续 5 分钟
以监控订单表为例,假设我们有一张 orders 表,想监控”最近 5 分钟订单量骤跌”:
查询(A):写一条 SQL,统计最近 5 分钟新增订单数
1 | SELECT |
表达式(B):设阈值条件
1 | WHEN last() OF A IS BELOW 10 |
持续时间:FOR 5m
翻译成人话就是:最近 5 分钟新增订单不到 10 单,且持续了 5 分钟,就告警。
这个规则非常实用——大促期间订单量突然暴跌,可能是支付接口挂了或者数据库连接池满了,第一时间发现能减少损失。
2. 配置通知渠道
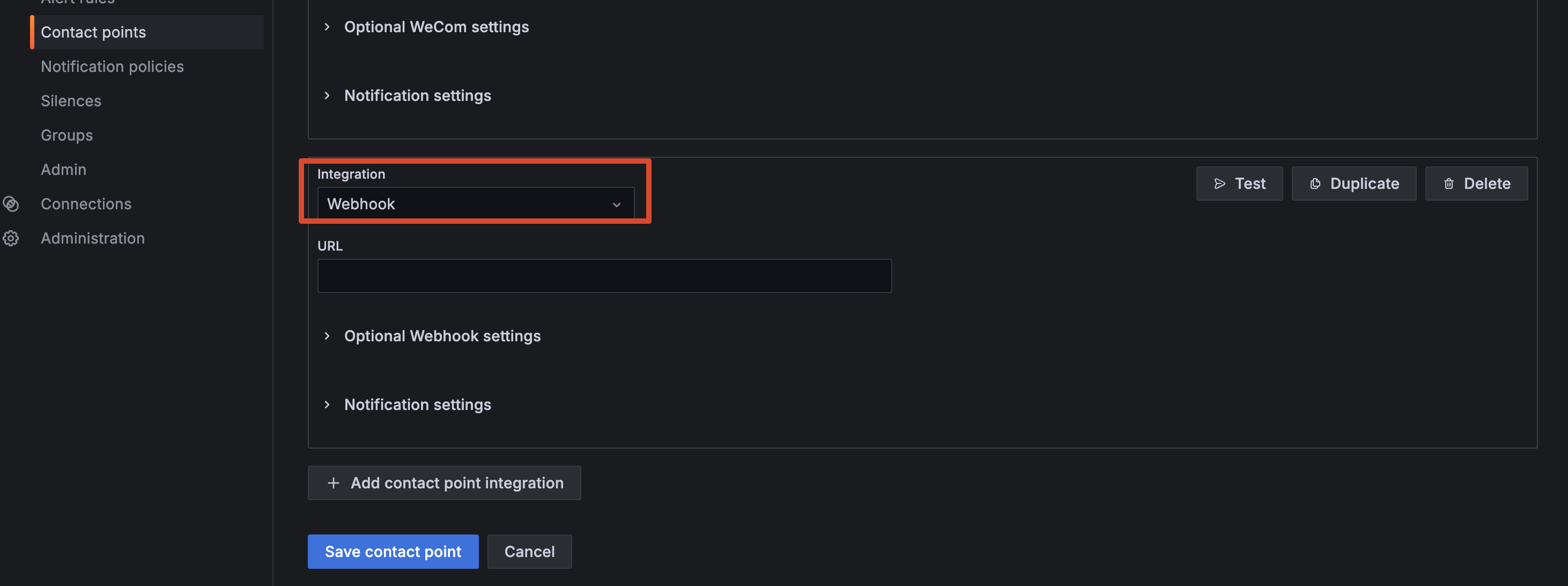
进入 Alerting → Contact points → Add contact point。
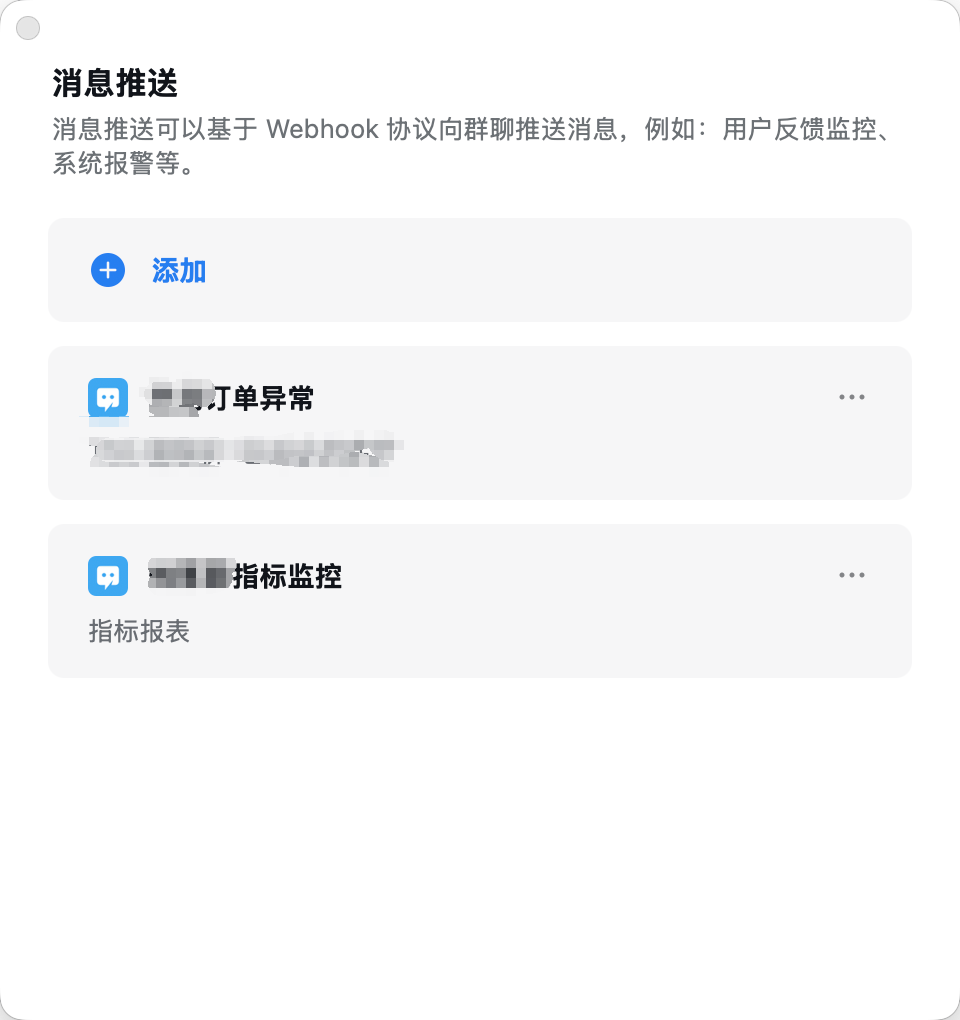
以企业微信为例,使用群消息推送方式:
- 在企业微信中新建一个告警通知群(或用现有群)
- 群管理员进入群设置,找到 消息推送,配置后获取 Webhook URL
- 回到 Grafana,Contact point 类型选 Webhook,填入上面的 URL
- 点 Test 确认企业微信能收到测试消息
下面是企业微信群消息推送的配置操作截图:
钉钉和飞书也支持类似的 Webhook 推送方式,具体配置步骤可以参考各平台的官方文档。
3. 设置通知策略
进入 Alerting → Notification policies。
这里控制告警怎么发。关键设置:
- 分组:相同标签的告警合并成一条消息,避免刷屏
- 静默:维护期间临时屏蔽告警
- 重试间隔:告警没恢复的话,隔多久再发一次
小团队建议一开始就简单配:所有告警都发到企业微信群,分组按 alertname,重试间隔 4 小时。后面有需要再细分。
实战:四个最实用的告警
分享几个小团队最常用的告警配置,直接抄就能用。
1. 订单量骤跌
大促或日常运营中,订单量突然暴跌往往意味着某个环节出了问题:
1 | 查询:SELECT COUNT(*) FROM orders WHERE created_at >= NOW() - INTERVAL 5 MINUTE |
2. 磁盘空间不足
磁盘满了是最常见的事故,提前告警能省很多麻烦:
1 | 查询:磁盘使用率 |
3. 数据库连接数过高
1 | 查询:SHOW STATUS LIKE 'Threads_connected' |
4. 慢查询激增
1 | 查询:SHOW STATUS LIKE 'Slow_queries' |
最佳实践
监控查询不要直连业务主库。
虽然上文例子中 Grafana 直接连的是业务 MySQL,但实际生产中强烈建议单独建一个监控数据库,把业务数据同步过去(比如用 Canal 或定时任务把关键表同步到只读库)。原因很简单:监控 SQL 再简单也是额外的查询负载,如果某天写了个复杂的统计 SQL,很可能拖慢业务主库的响应速度,得不偿失。
如果预算有限没有独立的数据库实例,至少也要在同一个 MySQL 实例上建一个单独的只读账号,并且监控 SQL 只走从库。别为了省事拿生产主库直接查。
常见问题
需要单独装 Prometheus 吗?
不需要。如果你的监控需求主要是业务数据(数据库里的订单、用户、流水等),直接用 Grafana 连 MySQL 就能做告警。如果还需要监控服务器 CPU、内存等系统指标,可以装一个 Grafana Agent,不需要上完整的 Prometheus 栈。
Grafana 告警和 Alertmanager 有什么区别?
简单说:Grafana 告警适合小团队,开箱即用;Alertmanager 适合大规模,有更强大的路由、去重、抑制能力。团队不超过 10 人的话,Grafana 自带的就够。
告警太多怎么办?
用好两个功能:分组(相同类型的告警合并成一条)和静默(维护期间不告警)。另外阈值别设太低,满足业务需求就行,不用一有波动就开始叫。
最后
监控告警这件事,最重要的是”先跑起来再优化”。别一开始就追求完美的架构,先用 Grafana 连上数据库,把最关键的几个业务指标监控上,能收到告警通知,就比 90% 的团队强了。
等团队规模和业务量上来了,再考虑加 Prometheus、Alertmanager 那一套也不迟。到那时候,Grafana 也不用扔——它可以继续做展示层,和 Prometheus 完美配合。